
Developing and implementing conformity tests is a time-consuming and fault-prone task. To reduce these efforts a new route must be tackled. The current way of specifying tests and implementing them includes too many manual steps. Based on the experience of testing electronic smart cards in ID documents like ePassports or ID cards, the author describes a new way of saving time to write new test specifications and to get test cases based on these specifications. It is possible, though, to improve the specification and implementation of tests significantly by using new technologies such as model based testing (MBT) and domain specific languages (DSL). I’m describing here my experience in defining a new language for testing smart cards based on DSL and models, and in using this language to generate both documents and test cases that can run in several test tools. The idea of using a DSL to define a test specification goes back to a tutorial of Markus Voelter and Peter Friese, hold during the conference Software Engineering 2010 in Paderborn.
With the introduction of smart cards in ID documents the verification of these electronic parts has become more and more important. The German Federal Office for Information Security (BSI) defines technical guidelines that specify several tests required to fulfill compliance. These guidelines include tests on the electrical and physical layer on the one hand, and tests on the application and data layer on the other hand. In this presentation the author focusses on the tests on the last two layers because these tests can be implemented completely in software.
In TR-03105 the BSI specifies several hundreds of test cases concerning the data format of smart cards and also the commands and protocols used to communicate with the chip.
In the past the typical approach was divided into several separate steps. At first the BSI specified a list of test cases and published them in a document that was written manually by an editor of the technical guideline. Then several test houses and vendors of test tools implemented all the test cases based on the specific guideline into their software solution. All these steps had to be done manually, which means: the software engineer of each institution read the guideline and implemented test case by test case in his special test environment. With every new version of the guideline this procedure had to be repeated again and again. At the beginning, the update cycle of these test specifications was very frequent because all the feedback collected in the field was included in the guideline and new versions were published in short intervals:
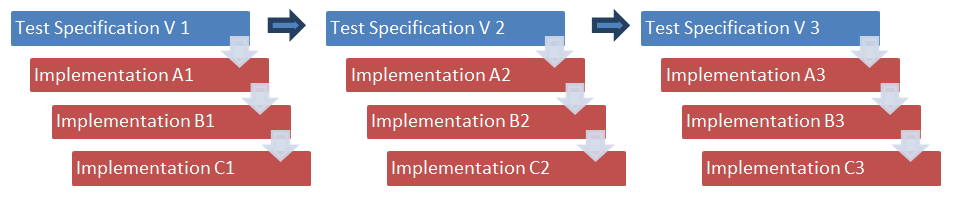
This way of specifying test specifications is inefficient because of the large number of manual steps. Doing the transformation from the test specification to the implementation is not only inefficient but also fault-prone: every test case in the guideline must be formulated in “prose” by the editor; every engineer must implement the test case in the respective programming language. Also the consistency of the tests must be maintained by the editor manually.
Furthermore, the writing of test specifications is an extensive part of conformity testing. The editor of such a specification in general uses a word processing software that is useful for e.g. writing small letters. But this kind of software is not really convenient for writing technical specifications like TR-03105. A typical problem is versioning of different types. It would be most helpful for developers, if the editor used the track changes mode when he changes test cases. This way the developer can easily detect changes. But this advantage depends on the activated mode. As soon as the editor forgets to activate the track changes mode the implementation of these changes becomes more and more complicated.
Due to an increasing number of new requirements of the applications running on smart cards the complexity of these systems becomes higher and higher. In Walter Fumys “Handbook of eID Security” the history of eID documents from purely visible ones to future versions is illustrated. This complexity in these applications will result in so many test cases that the current approach of writing and implementing test specifications is a blind alley.
With recent results of Model Driven Software Development (MDSD) this blind alley can be avoided. New techniques and tools allow us now to switch from the manual parts to a more automated procedure. The goal is to write only one “text” that can be used as a source for all the test tools. The solution is a model that defines the test cases and a transformation of this model to other platforms or formats.
With this new approach, the process of specifying tests can be reduced to the interesting part where the editor can use his creativity to conceive new tests and not to use his office software to write tests.
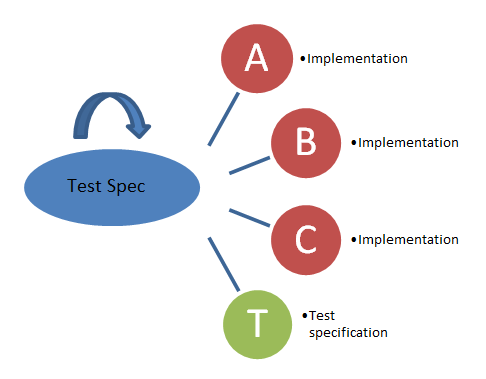
Defining a language that describes the test case is the basis for this procedure. This grammar can be used to model test cases, and based on this model all the artifacts needed can be generated. The following figure visualizes this process: there is one Meta test specification that is used to generate not only the human-readable document but also the tool-specific test cases for every test environment.
One solution to define a language is Xtext. With Xtext the user gets a complete environment based on Eclipse to develop his own domain specific language (DSL). One of the benefits of Xtext is the editor that is generated automatically by the tool itself. This editor includes code-completion, syntax coloring, code-folding and outline view. This editor is very helpful to write test cases. Every test case that is not compliant with the grammar is marked as faulty. So the editor of the specification can recognize this wrong test case directly like a software developer in Integrated Development Environments (IDE).
Additionally, the user can implement generators to generate code for the scope platform. These generators are called by the Modeling Workflow Engine (MWE). These generators are powerful and productive tools to provide test cases for different platforms.
In the public sector it is more and more important to write barrier-free documents. It takes a lot of time to write a barrier-free document based on a typical technical specification. With a generator that produces a human-readable document the author of the test specifications can use generic templates that produce barrier-free documents in an automatic way because the generator can use rules that fulfill even these standards.
Once the user has generated a new test specification or a new test case based on any test tool, he can modify this document by adding some special features, e.g. a special library to one test case. With a model based test specification it is possible to re-import this modified artifact into the model to assure persistency. The author presented and published his first experience at ICST 2011.
This approach helps to write test specifications in a technical way on a Meta level but it does not focus on the content of the test specification. Thus, the approach helps to write the document but it does not help to produce any content needed. Currently, the quality of a test specification is dependent from the background of the author. With his knowledge of protocols and corresponding pitfalls he can specify interesting test cases. But many test cases contain the same scenarios (wrong length, set a value to zero, use maximum or minimum value and so on). It would be more reasonable and economical if the author could focus on special test cases for the relevant protocols and their pitfalls and “standard” test cases would be generated automatically. On the other hand, test specifications written by humans always run the risk of being inconsistent, error-prone and imprecise. Additionally, it is always rather time-consuming to write test specifications manually.
To focus and solve problems as described above a consortium of BSI, HJP Consulting, s-lab Software Quality Lab (University of Paderborn) and TÜViT started a research project, namely MOTEMRI (Modellbasiertes Testen mit Referenzimplementierung). In MOTEMRI a model is developed that contains all relevant information of the popular protocol PACE. This model is specified in UML so everybody who is interested can read and modify the diagrams easily. In this way it is possible to adapt new protocols into the model like PACE or new versions developed in the future. Based on the model, algorithms generate test cases automatically. Thereby the knowledge of designing test cases is enacted into software, independent from the knowledge of the author of the test specification. By the way, this procedure also allows using various “wrong” values for negative test cases. Negative test cases are generated automatically and access different “wrong” values. Using random values allows better testing and ensures better chip implementations.